HTML und XHTML
Grundlagen
Was tut der Browser?
Die Aufgaben eines Browsers sind gar nicht mal so schwer zu verstehen.
Sie dann tatsächlich auszuführen, stellt ihn dann schon vor wesentlich grössere Probleme, aber das ist
ein anderes Kapitel. Hier hab ich nun mal versucht, schematisch darzustellen, was ein Browser macht.
Ich empfehle dir, die sechs Schritte der Reihe nach anzuklicken und zuzusehen, wie sich das Bild
vervollständigt.
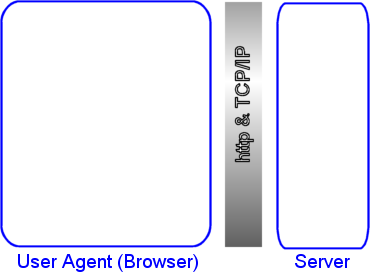









1. Alles fängt damit an, dass du deinen Browser anweisest, eine bestimmte Seite zu laden.
Zum Beispiel klickst du auf einen Link oder tippst eine URL ein.
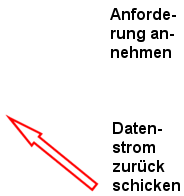
2. Dein Browser gibt diese Anforderung aufs Netz. Das HTTP-Protokoll, das er dabei verwendet,
sorgt mit seinen Regeln dafür, dass die Anforderung bei dem Server landet, der in der URL genannt wurde.
3. Was der Server alles macht, wollen wir nicht im Detail betrachten. Er wird aber irgendwann
einen Strom von Daten zurücksenden, den der Browser als HTML-Daten erkennen sollte (Wir werden noch
sehen, warum).
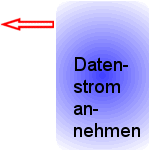
4. Die Daten, die vom Server gesandt wurden, werden nun vom Browser entgegen genommen und nach den Regeln von
HTML zerlegt. Der Fachausdruck dafür heisst "Parsing".
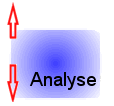
5. Bei der Analyse des HTML-Textes kann der Browser z.B. erkennen, dass nun ein Bild verlangt ist. Dieses befindet
sich aber in einem separaten File, und so wird der Browser dieses File erneut vom Server anfordern.
6. Die Elemente, die der Browser selbst interpretieren kann (HTML-Text) oder sonstwie fertig erhalten hat (Bilder),
gibt er nun auf dem Bildschirm wieder. Er kann dies auch tun, währenddem er weitere Files anfordert und erwartet.
Abbildung 1: Was der Browser tut
Das Runterladen selbst funktioniert genau gleich für Bilder wie für alle andern Inhaltsarten, die wir
aufgezählt haben. Die Daten, die durch die Leitung auf unsern PC runtergetröpfelt kommen, sind mit einer
Art Beipackzettel versehen, in welchem ihre Art genau beschrieben ist. Daraus erkennt der Browser dann,
ob es sich nun um HTML-Text handelt (den er analysieren muss) oder um anderes, wie z.B. Bilder.
Natürlich ist das nicht alles immer ganz einfach:
In vielen Fällen kommt der Browser mit den Daten ganz gut zurecht und ist zum Beispiel ohne weiteres
in der Lage, Texte und Bilder gefällig auf dem Bildschirm wiederzugeben. Es gibt aber auch anderes.
Flash und Filmformate wie z.B. Quicktime übersteigen normalerweise die Fähigkeiten eines Browsers,
und nichts garantiert uns, dass nicht eine findige Softwareschmiede künftig mit neuen Ideen und Datenformaten
aufwartet, mit denen unser Browser nie im Leben gerechnet hätte.
In diesem Zusammenhang taucht dann jeweils das Wort plug-in auf:
Das sind Zusatzprogramme,
die der Browser bei Bedarf zu Hilfe rufen kann, damit sie die entsprechenden Daten wiedergeben.
In der Praxis bedeutet das, dass für solche Daten zwar separate Programme benötigt werden, dass aber
der Browser auf Grund des Beipackzettels die richtigen Plug-Ins auswählt und aufruft, vorausgesetzt
natürlich, dass sie installiert sind. Für uns, die wir vor dem Bildschirm sitzen und das Resultat
besichtigen, sind solche Vorgänge kaum wahrnehmbar.
Seitdem dieser Kurs verfasst worden ist, sind nun doch schon mehrere Jahre ins Land gegangen.
In dieser Zeit sind die Browser — vor allem unter dem Druck von HTML5 — viel leistungsfähiger
und Vielfältiger geworden und können viele unterschiedliche Formate (vor allem im Bereich Multimedia)
ohne die Hilfe von Plug-Ins wiedergeben. Auch wenn das oben gesagte weiterhin gilt, ist es mittlerweile
nicht mehr so wichtig — Plug-Ins sind im Abnehmen und langsam vom Aussterben bedroht.
 Home
Einleitung
Grundlagen
Was ist eine Webseite?
Was enthält sie?
Was tut der Browser?
Die Enteckung der Langsamkeit
Was ist HTML und XHTML?
Standards
Begriffe
Quiz
Elemente und Attribute
HTML-Dokumente
strukturelles Markup
Site Management
Hyperlinks
Bilder und Grafiken
ohne Fehl und Tadel
Spezialfälle
Tabellen
Formulare
Schlussbemerkungen
Home
Einleitung
Grundlagen
Was ist eine Webseite?
Was enthält sie?
Was tut der Browser?
Die Enteckung der Langsamkeit
Was ist HTML und XHTML?
Standards
Begriffe
Quiz
Elemente und Attribute
HTML-Dokumente
strukturelles Markup
Site Management
Hyperlinks
Bilder und Grafiken
ohne Fehl und Tadel
Spezialfälle
Tabellen
Formulare
Schlussbemerkungen